本文转自:https://www.imooc.com/article/24822
本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
喜欢的话麻烦点下Star哈
文章同步发于我的个人博客:
本文是微信公众号【Java技术江湖】的《Java并发指南》其中一篇,本文大部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。
该系列博文会告诉你如何全面深入地学习Java并发技术,从Java多线程基础,再到并发编程的基础知识,从Java并发包的入门和实战,再到JUC的源码剖析,一步步地学习Java并发编程,并上手进行实战,以便让你更完整地了解整个Java并发编程知识体系,形成自己的知识框架。
为了更好地总结和检验你的学习成果,本系列文章也会提供一些对应的面试题以及参考答案。
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
Fork/Join框架介绍
Fork/Join框架是Java7提供的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。使用工作窃取(work-stealing)算法,主要用于实现“分而治之”。
简介
通常,使用Java来开发一个简单的并发应用程序时,会创建一些Runnable对象,然后创建对应的Thread 对象来控制程序中这些线程的创建、执行以及线程的状态。自从Java 5开始引入了Executor和ExecutorService接口以及实现这两个接口的类(比如ThreadPoolExecutor)之后,使得Java在并发支持上得到了进一步的提升。
执行器框架(Executor Framework)将任务的创建和执行进行了分离,通过这个框架,只需要实现Runnable接口的对象和使用Executor对象,然后将Runnable对象发送给执行器。执行器再负责运行这些任务所需要的线程,包括线程的创建,线程的管理以及线程的结束。
Java 7则又更进了一步,它包括了ExecutorService接口的另一种实现,用来解决特殊类型的问题,它就是Fork/Join框架,有时也称分解/合并框架。
Fork/Join框架是用来解决能够通过分治技术(Divide and Conquer Technique)将问题拆分成小任务的问题。在一个任务中,先检查将要解决的问题的大小,如果大于一个设定的大小,那就将问题拆分成可以通过框架来执行的小任务。如果问题的大小比设定的大小要小,就可以直接在任务里解决这个问题,然后,根据需要返回任务的结果。下面的图形总结了这个原理。
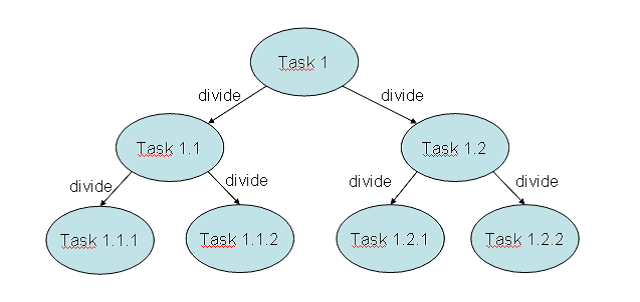
没有固定的公式来决定问题的参考大小(Reference Size),从而决定一个任务是需要进行拆分或不需要拆分,拆分与否仍是依赖于任务本身的特性。可以使用在任务中将要处理的元素的数目和任务执行所需要的时间来决定参考大小。测试不同的参考大小来决定解决问题最好的一个方案,将ForkJoinPool类看作一个特殊的 Executor 执行器类型。这个框架基于以下两种操作。
- 分解(Fork)操作:当需要将一个任务拆分成更小的多个任务时,在框架中执行这些任务;
- 合并(Join)操作:当一个主任务等待其创建的多个子任务的完成执行。
Fork/Join框架和执行器框架(Executor Framework)主要的区别在于工作窃取算法(Work-Stealing Algorithm)。与执行器框架不同,使用Join操作让一个主任务等待它所创建的子任务的完成,执行这个任务的线程称之为工作者线程(Worker Thread)。工作者线程寻找其他仍未被执行的任务,然后开始执行。通过这种方式,这些线程在运行时拥有所有的优点,进而提升应用程序的性能。
为了达到这个目标,通过Fork/Join框架执行的任务有以下限制。
- 任务只能使用fork()和join() 操作当作同步机制。如果使用其他的同步机制,工作者线程就不能执行其他任务,当然这些任务是在同步操作里时。比如,如果在Fork/Join 框架中将一个任务休眠,正在执行这个任务的工作者线程在休眠期内不能执行另一个任务。
- 任务不能执行I/O操作,比如文件数据的读取与写入。
- 任务不能抛出非运行时异常(Checked Exception),必须在代码中处理掉这些异常。
Fork/Join**框架**的核心是由下列两个类组成的。
- ForkJoinPool:这个类实现了ExecutorService接口和工作窃取算法(Work-Stealing Algorithm)。它管理工作者线程,并提供任务的状态信息,以及任务的执行信息。
- ForkJoinTask:这个类是一个将在ForkJoinPool中执行的任务的基类。
Fork/Join框架提供了在一个任务里执行fork()和join()操作的机制和控制任务状态的方法。通常,为了实现Fork/Join任务,需要实现一个以下两个类之一的子类。
- RecursiveAction:用于任务没有返回结果的场景。
- RecursiveTask:用于任务有返回结果的场景。
工作窃取算法介绍
工作窃取(work-stealing)算法优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。

Fork/Join框架基础类
- ForkJoinPool: 用来执行Task,或生成新的ForkJoinWorkerThread,执行 ForkJoinWorkerThread 间的 work-stealing 逻辑。ForkJoinPool 不是为了替代 ExecutorService,而是它的补充,在某些应用场景下性能比 ExecutorService 更好。
- ForkJoinTask: 执行具体的分支逻辑,声明以同步/异步方式进行执行
- ForkJoinWorkerThread: 是 ForkJoinPool 内的 worker thread,执行
- ForkJoinTask, 内部有 ForkJoinPool.WorkQueue来保存要执行的ForkJoinTask。
- ForkJoinPool.WorkQueue:保存要执行的ForkJoinTask。
基本思想
- ForkJoinPool 的每个工作线程都维护着一个工作队列(WorkQueue),这是一个双端队列(Deque),里面存放的对象是任务(ForkJoinTask)。
- 每个工作线程在运行中产生新的任务(通常是因为调用了 fork())时,会放入工作队列的队尾,并且工作线程在处理自己的工作队列时,使用的是 LIFO 方式,也就是说每次从队尾取出任务来执行。
- 每个工作线程在处理自己的工作队列同时,会尝试窃取一个任务(或是来自于刚刚提交到 pool 的任务,或是来自于其他工作线程的工作队列),窃取的任务位于其他线程的工作队列的队首,也就是说工作线程在窃取其他工作线程的任务时,使用的是 FIFO 方式。
- 在遇到 join() 时,如果需要 join 的任务尚未完成,则会先处理其他任务,并等待其完成。
- 在既没有自己的任务,也没有可以窃取的任务时,进入休眠。
代码演示
大家学习时,通常借助的例子都类似于下面这段:
1 | @Slf4j |
重点注意
需要特别注意的是:
ForkJoinPool 使用submit 或 invoke 提交的区别:invoke是同步执行,调用之后需要等待任务完成,才能执行后面的代码;submit是异步执行,只有在Future调用get的时候会阻塞。
这里继承的是RecursiveTask,还可以继承RecursiveAction。前者适用于有返回值的场景,而后者适合于没有返回值的场景
这一点是最容易忽略的地方,其实这里执行子任务调用fork方法并不是最佳的选择,最佳的选择是invokeAll方法。
1
2
3
4
5
6leftTask.fork();
rightTask.fork();
替换为
invokeAll(leftTask, rightTask);
具体说一下原理:对于Fork/Join模式,假如Pool里面线程数量是固定的,那么调用子任务的fork方法相当于A先分工给B,然后A当监工不干活,B去完成A交代的任务。所以上面的模式相当于浪费了一个线程。那么如果使用invokeAll相当于A分工给B后,A和B都去完成工作。这样可以更好的利用线程池,缩短执行的时间。
微信公众号
个人公众号:程序员黄小斜
微信公众号【程序员黄小斜】新生代青年聚集地,程序员成长充电站。作者黄小斜,职业是阿里程序员,身份是斜杠青年,希望和更多的程序员交朋友,一起进步和成长!这一次,我们一起出发。
关注公众号后回复“2019”领取我这两年整理的学习资料,涵盖自学编程、求职面试、算法刷题、Java技术、计算机基础和考研等8000G资料合集。

技术公众号:Java技术江湖
微信公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,专注于 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
关注公众号后回复“PDF”即可领取200+页的《Java工程师面试指南》强烈推荐,几乎涵盖所有Java工程师必知必会的知识点。


